VERE - Web-1 - Quick
Published at Jan 18, 2025
How quick are you? Can you follow the path to the flag before time runs out?
This challenge involves navigating through a series of interconnected HTML files, with each page containing clues or links to the next. The goal is to locate the hidden flag embedded within one of these files before time runs out. The intended solution involves scripting the navigation process using BeautifulSoup, a Python library for parsing HTML and XML documents.
Starting the Challenge
The first thing I did was pull up the website that was linked in the challenge description, revealing an… interesting webpage with some questionable CSS:
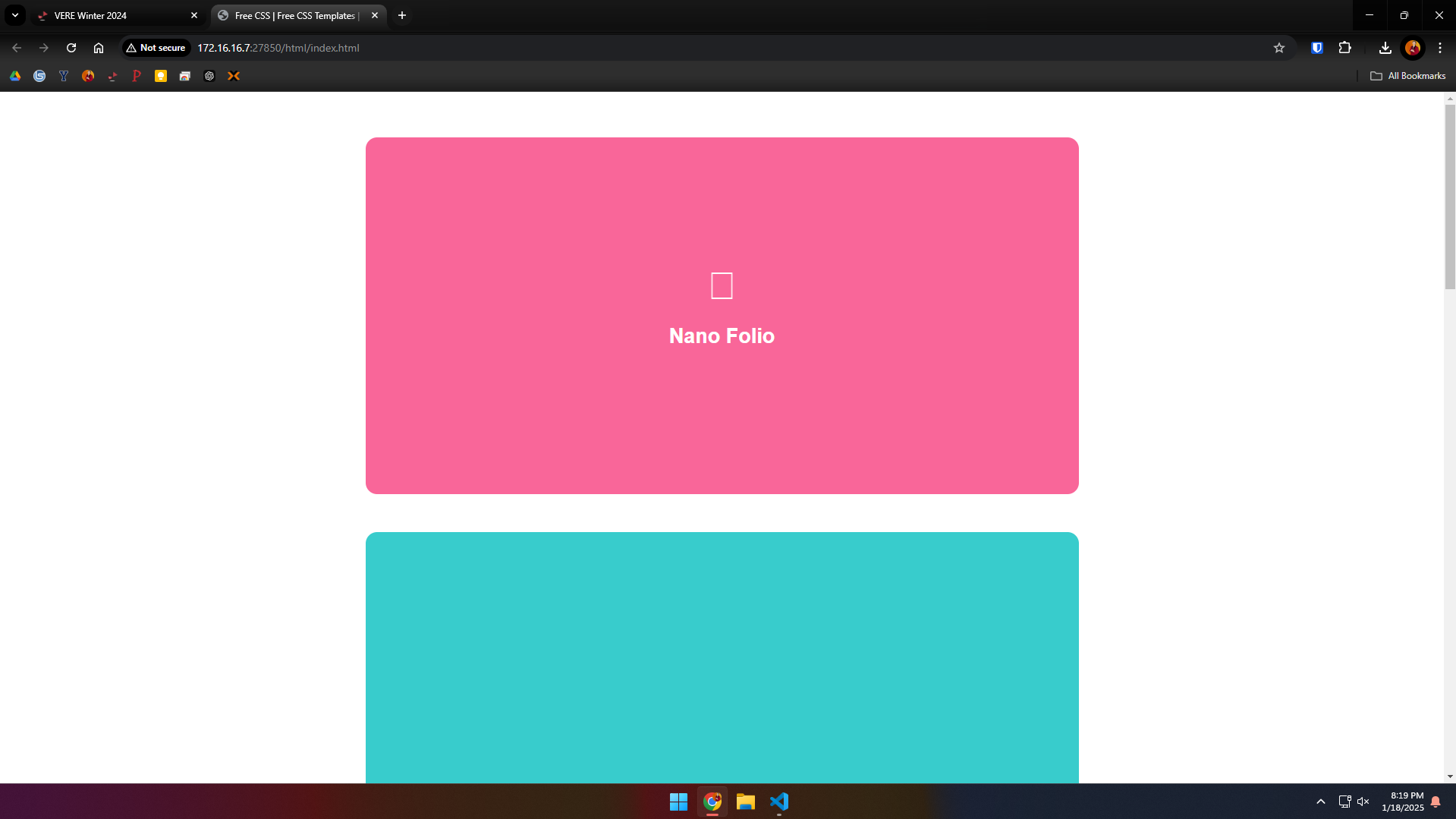
Scrolling down I could see some elements with series of random numbers and letters that appeared to be hyperlinks when I hovered over them. When I clicked on these elements, I was redirected to a new similar-looking page, but the random links had been altered.
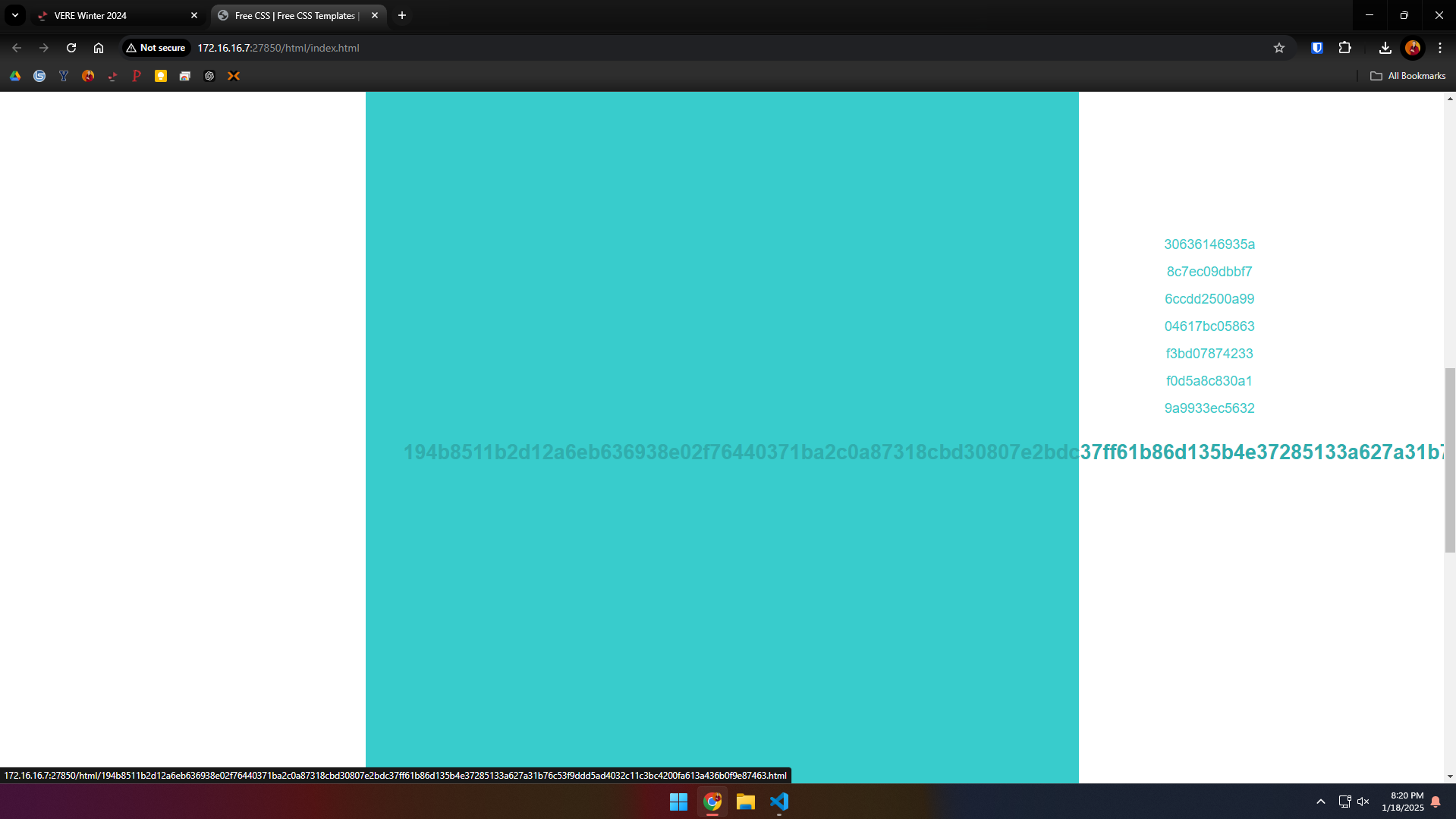 I found that if I waited too long on a page, it would time out, so I knew I had to be fast. This was the path I’d need to take, parsing through the HTML to find the next link and going to it until I found the flag, and I had to do it fast enough to beat the clock.
I found that if I waited too long on a page, it would time out, so I knew I had to be fast. This was the path I’d need to take, parsing through the HTML to find the next link and going to it until I found the flag, and I had to do it fast enough to beat the clock.
How I solved it
The challenge author recommended using Beautiful Soup, which is a Python library used for web scraping and parsing HTML and XML documents. It provides tools to navigate, search, and modify the parse tree, making it easier to extract specific elements like tags, attributes, and text from web pages, and is commonly used for automating data extraction from websites.
I also needed the lxml Python library for processing XML and HTML documents, and the requests library to simplify sending and receiving HTTP request data.
apt install python3-bs4
pip install beautifulsoup4 lxml requestsI then created a Python script:
nano soup.py import requests
from bs4 import BeautifulSoup
base_url = "http://172.16.16.7:27850/html/"
current_file = "index.html"
# Loop until the flag is found
while True:
response = requests.get(f"{base_url}{current_file}")
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Check if the current file contains the flag
if "vere{" in response.text:
print(f"Flag found in {current_file}!")
flag = response.text.split("vere{")[1].split("}")[0]
print(f"Flag: vere{{{flag}}}")
break
# Find the next link
next_link = soup.find('a', href=True, text=lambda x: x and x.endswith(".html"))
if not next_link:
print("No further link found!")
break
# Update the current file to the next link
current_file = next_link['href']
print(f"Following link to: {current_file}")How It Works
- My script starts by defining the base_url for the HTML directory and the initial file (index.html).
- The requests library is used to send an HTTP GET request to fetch the HTML content of the current file.
- The HTML content is parsed using BeautifulSoup to locate links within the page.
- The script searches for the flag by checking if the string
vere{exists in the HTML content. If found, it extracts the flag and breaks out of the loop. - If the flag isn’t in the current file, the script identifies the next link (an
<a>element with an associated href) that ends with .html and updates current_file to follow it. - This process continues until the flag is found or no further links are available, which would indicate that it went too slow.
Fortunately, I was fast enough! The script ran for about ten seconds, and scraped through over a hundred URLs for <a> tags, as it searched for the flag. Here is a screenshot of the end of my output:

Flag
vere{soup_is_yummyyyyyy_except_f0r_t0mat0_soup_BL3H_3f04e37458f8}